Las estadísticas se han convertido en una parte integral de la vida. La gente lo encuentra en todas partes. Sobre la base de las estadísticas, se extraen conclusiones sobre dónde y qué enfermedades son comunes, lo que tiene más demanda en una región en particular o entre un determinado segmento de la población. Sobre la base de las estadísticas, incluso se basa la construcción de programas políticos de candidatos para el gobierno. También son utilizados por las cadenas minoristas cuando compran productos, y los fabricantes se guían por estos datos en sus propuestas.
Las estadísticas juegan un papel importante en la sociedad y afectan a cada miembro individual, incluso en cosas pequeñas. Por ejemplo, si según las estadísticas, la mayoría de las personas prefieren los colores oscuros en la ropa en una ciudad o región en particular, entonces será extremadamente difícil encontrar un abrigo floral amarillo brillante en los puntos de venta locales. ¿Pero cuáles son los valores que componen estos datos? Por ejemplo, ¿qué es "significación estadística"? ¿Qué se entiende exactamente por esta definición?
Que es esto
La estadística como ciencia consiste en una combinación de diferentes cantidades y conceptos. Uno de ellos es el concepto de "significación estadística". Este es el nombre del valor de las variables, la probabilidad de la aparición de otros indicadores en los que es insignificante.

Por ejemplo, 9 de cada 10 personas se pusieron zapatos de goma en los pies durante una caminata matutina en busca de hongos en el bosque de otoño después de una noche lluviosa. La probabilidad de que en algún momento 8 de ellos se usen en mocasines de lona es insignificante. Por lo tanto, en este ejemplo particular, el número 9 es una cantidad llamada "significación estadística".
En consecuencia, si desarrollamos el ejemplo práctico que sigue, las zapaterías compran grandes cantidades de botas de goma al final de la temporada de verano que en otras épocas del año. Entonces, la magnitud del valor estadístico afecta la vida ordinaria.
Por supuesto, en cálculos complejos, por ejemplo, al predecir la propagación de virus, se tiene en cuenta una gran cantidad de variables. Pero la esencia misma de determinar un indicador significativo de datos estadísticos es similar, independientemente de la complejidad de los cálculos y el número de valores variables.
¿Cómo calcular?
Se utiliza para calcular el valor del indicador "significancia estadística" de la ecuación. Es decir, se puede argumentar que en este caso, todo lo decide la matemática. La opción de cálculo más simple es una cadena de acciones matemáticas en la que participan los siguientes parámetros:
- dos tipos de resultados obtenidos de encuestas o el estudio de datos objetivos, por ejemplo, los montos para los que se realizan las compras, denotado por a y b;
- el indicador de tamaño de muestra para ambos grupos es n;
- el valor de la parte de la muestra combinada es p;
- El concepto de error estándar es SE.
El siguiente paso es determinar el indicador de prueba general - t, su valor se compara con el número 1.96. 1.96 es el valor promedio que transmite un rango de 95% de acuerdo con la función de distribución t de Student.
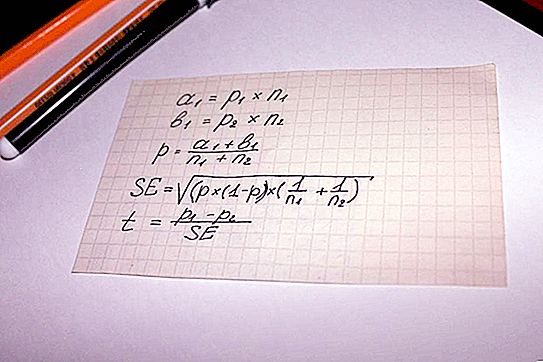
A menudo surge la pregunta de cuál es la diferencia entre los valores de ny p. Este matiz se aclara simplemente usando un ejemplo. Suponga que se calcula la importancia estadística de la lealtad a un producto o marca de hombres y mujeres.
En este caso, las designaciones de letras serán las siguientes:
- n es el número de encuestados;
- p es el número de personas satisfechas con el producto.
El número de mujeres entrevistadas en este caso se indicará como n1. En consecuencia, hombres - n2. Los dígitos "1" y "2" para el carácter p tendrán el mismo significado.
La comparación del indicador de prueba con los valores promedio de las tablas de cálculo del estudiante se convierte en lo que se llama "significancia estadística".
¿Qué se entiende por verificación?
Los resultados de cualquier cálculo matemático siempre se pueden verificar; a los niños se les enseña esto en los grados de primaria. Es lógico suponer que una vez que los indicadores estadísticos se determinan utilizando una cadena de cálculos, se verifican.
Sin embargo, la verificación de la significación estadística no es solo matemática. Las estadísticas tratan con una gran cantidad de variables y diversas probabilidades, que están lejos de ser siempre calculables. Es decir, si volvemos al ejemplo con los zapatos de goma que se dan al comienzo del artículo, la construcción lógica de los datos estadísticos, en los que se basarán los compradores de bienes para las tiendas, puede verse afectada por el clima seco y cálido, que no es típico para el otoño. Como resultado de este fenómeno, la cantidad de personas que compran botas de goma disminuirá y los puntos de venta sufrirán pérdidas. La fórmula matemática, por supuesto, no puede prever la anomalía climática. Este momento se llama "error".
Esta es precisamente la probabilidad de tales errores que se tiene en cuenta al verificar el nivel de significancia calculado. Tiene en cuenta tanto los indicadores calculados como los niveles de significancia aceptados, así como las cantidades, llamadas condicionalmente hipótesis.
¿Cuál es el nivel de significancia?
El concepto de "nivel" se incluye en los criterios principales de significación estadística. Se utiliza en estadística aplicada y práctica. Este es un tipo de valor que tiene en cuenta la probabilidad de posibles desviaciones o errores.
El nivel se basa en la identificación de diferencias en las muestras terminadas, le permite establecer su importancia o, por el contrario, la aleatoriedad. Este concepto no solo tiene significados digitales, sino también sus desciframientos peculiares. Explican cómo entender el significado, y el nivel en sí mismo se determina comparando el resultado con el índice promedio, esto revela el grado de importancia de las diferencias.

Por lo tanto, es posible imaginar el concepto de un nivel simplemente: es un indicador de error permisible, probable o error en las conclusiones obtenidas de los datos estadísticos obtenidos.
¿Qué niveles de significación se utilizan?
La importancia estadística de los coeficientes de probabilidad de un error en la práctica se basa en tres niveles básicos.
El primer nivel es el umbral en el que el valor es del 5%. Es decir, la probabilidad de error no supera un nivel de significancia del 5%. Esto significa que la confianza en la impecabilidad e impecabilidad de las conclusiones hechas sobre la base de la investigación estadística es del 95%.
El segundo nivel es el umbral del 1%. En consecuencia, esta cifra significa que puede guiarse por los datos obtenidos durante los cálculos estadísticos con una confianza del 99%.
El tercer nivel es 0.1%. Con este valor, la probabilidad de un error es igual a una fracción de un porcentaje, es decir, los errores se eliminan prácticamente.
¿Qué es una hipótesis en estadística?
Los errores como concepto se dividen en dos direcciones con respecto a la aceptación o rechazo de la hipótesis nula. Una hipótesis es un concepto que, por definición, oculta un conjunto de resultados de encuestas, otros datos o declaraciones. Es decir, una descripción de la distribución de probabilidad de algo relacionado con el tema de la contabilidad estadística.

La hipótesis en cálculos simples es dos: cero y alternativa. La diferencia entre ellos es que la hipótesis nula se basa en la idea de que no hay diferencias fundamentales entre las muestras que participan en la determinación de la significación estadística, y la alternativa es completamente opuesta a ella. Es decir, una hipótesis alternativa se basa en la presencia de una diferencia significativa en los datos de las muestras.
Cuales son los errores?
Los errores como concepto en estadística dependen directamente de la adopción de una hipótesis particular como verdadera. Se pueden dividir en dos direcciones o del mismo tipo:
- el primer tipo se debe a la adopción de la hipótesis nula, que resultó ser incorrecta;
- el segundo es causado por seguir una alternativa.

El primer tipo de error se llama falso positivo y ocurre con bastante frecuencia en todas las áreas donde se utilizan estadísticas. En consecuencia, el error del segundo tipo se llama falso negativo.



